- Functional Parallel Algorithms Guy Blelloch gave a fantastic invited talk on the analysis of parallel algorithms. His work -- now 15 years old -- uses a parallelized version of the lambda calculus as a fundamental model of computation. The parallelism is exactly that expected from a pure functional language: in a function application, the operator and operand are evaluated in parallel. Using this simple model, it is possible to characterize both the "work" (roughly, reduction steps in a sequential semantics) and the "span" (roughly, longest sequence of data dependencies). The span can be understood as the minimum time needed to perform a computation given an unlimited supply of parallel processors. Guy gave a big-step cost semantics for his model, and then walked through several variations of sorting algorithms, analyzing them all. Elegant and clearly-presented.
- Rethinking Supercompilation Supercompilation is, roughly, partial evaluation combined with case splitting -- that is, you attempt to symbolically execute the program at compile-time, and insert case analysis when the value of an unknown is required. Neil Mitchell's paper gives a new architecture for supercompilation that is both simple and performant. The main insight seems to be the handling of let bindings: the intermediate language is a variant of ANF, which forces a lot of design choices in a good direction. This is one of the papers we read before heading to ICFP. The talk was quite good, and helped clarify many details from the paper.
- Parametricity and Dependent Types This talk addressed a question I've been curious about for a while: what does parametricity look like in a dependently-typed setting? The talk showed that a single logical relation can be given covering all pure type systems (PTS) at once. The trick is to use the expressive power of PTS to give the logical relation as a type-to-type transformation, where the types in the range may land in a different location in the lambda cube from those in the domain. If you specialize the relation to, say, System F, it's easy to see how the resulting types correspond precisely to the definition of the relation in second-order logic. I still haven't had time to sit down and work through the details, partly because I need to learn more about PTS first. Very curious to see what the impact of this paper turns out to be.
Tuesday, October 12, 2010
ICFP roundup, day #3
I missed a lot of day 3, but here were some standouts:
Sunday, October 10, 2010
ICFP roundup, day #2
Here are the talks from day #2 that really stood out for me:
- The impact of higher-order state and control effects on local relational reasoning This was probably my favorite result presented at the conference, though not my favorite talk. The work studies two orthogonal language features -- higher-order state and control -- and characterizes reasoning principles valid in the presence or absence of these features. The reasoning principles, like the features themselves, are orthogonal. I believe in each case the model is fully abstract, but this is due more to the use of biorthogonality than the particulars of each feature. Still, the model seems quite insightful and I'm looking forward to reading the paper.
- Distance makes the types grow stronger Jason Reed gave a fun talk on "differential privacy" and how it can be achieved via a type system. The work is in the area of anonymity of data: how can you release enough data to perform useful statistical work without also leaking private information? A timely and surprisingly difficult problem. Differential privacy, if I understood it correctly, is a kind of metric-continuity: if you change a data set by a small amount, say by deleting a record, the information you can glean from the data set should likewise change by a small amount. The type system is meant to enforce this property.
- Fortifying macros Ryan Culpepper gave an excellent talk on his macro system, known as syntax-parse. The talk told a convincing story about both the power of macros, and the difficulty of making them robust. As is often the case, error checking and reporting code easily dwarfs and obscured the intended functionality of macros. The syntax-parse system allows you to write macros in a very direct style, but still provide robust error handling, most of which you get for free from the system. To make this work, syntactic forms are given a more explicit treatment: you can define a form like binding-list-without-repetitions, give it a user-friendly name and appropriate error handling, and then use it freely in macros. Such extra structure helps to keep macros at a high level of abstraction, and to give the system the right hooks to perform error handling on its own.
Thursday, October 7, 2010
ICFP roundup, day #1
Update: my apologies if this post appears multiple times in RSS: I had a bit of a tussle with blogger.
Here are some of the talks from ICFP day 1 that I got something out of:
Here are some of the talks from ICFP day 1 that I got something out of:
- ML: Metalanguage or Object Language? Mike Gordon's invited talk was a biographical talk about Milner. He used flashy presentation software that would've been annoying for a technical talk, but worked well for a talk with a lot of photos and scanned letters. One of my favorite anecdotes was the following: Dana Scott, having at last produced a model of the untyped lambda calculus, had become embarrassed by his previous insistence that only the typed version was worthwhile. He wrote a letter to Milner, asking him to stop working with LCF (which was based on the typed version) and instead work with the untyped calculus. Milner stuck with LCF -- writing, basically, "well, I've already got all this code, you see..."
- Functional Pearl: Every Bit Counts This was a great talk (and an even greater paper). The idea is to build coding schemes based on question-answer games, where every question adds some information ("every bit counts"). The paper presents a beautiful collection of combinators for describing such games, which yield correct-by-construction encoders and decoders. Perhaps the neatest aspect of the approach is that codes can be built such that, for example, every possible bit sequence is (a prefix of) a code for a well-typed program. The authors plan to explore applications to typed bytecodes, as in the CLR or JVM.
- Lolliproc: to Concurrency from Classical Linear Logic via Curry-Howard and Control Mazurak takes a new stab at Curry-Howard for concurrency. From a high level, the system seems beautifully simple, and the laws you gain from classical linear logic are interpreted directly as concurrency primitives. From a type theoretic perspective, the work seemed insightful, but from a pure concurrency perspective it was exploring well-trodden ground. Definitely worth keeping an eye on.
- Abstracting Abstract Machines I've seen Van Horn's talk before, but it's nice even the second time around. His work shows how to construct static analyses in a turn-the-crank fashion, using reduction semantics. The key point is to factor every component of the program state that lives in an infinite domain through a heap: each time you want to yield an inhabitant of the domain, you must allocate a new address. You can then bound the size of the heap, and the various ways of doing this yield various well-known analyses. Very cool!
- Lazy Tree Splitting Mike Rainey's talk was about work on the Manticore project. They are dealing with nested data parallelism and have taken a work-stealing approach. Mike's talk focused on a technique for splitting up work as late as possible, when one processor detects that others are idle. Since work is tree-structured, you need a way to quickly split up the tree of work and communicate parts of it to other threads. The technique appears to give robust, scalable performance in practice, which is what they were after: more eager approaches only scale well with application-specific tuning.
- Logical Types for Untyped Languages I've also seen Tobin-Hochstadt's talk before, but the conference version was a worthwhile re-run! This work takes occurrence typing in a new, very elegant direction, by internalizing propositional logic directly into the type system. There's been a lot of work using theorem provers within type checkers (for, say, gradual typing), but this type system can do basic logical reasoning without a theorem prover, and in a robust way. As usual from the PLT group, the work was directly motivated by, and tested against, a large body of real code.
Monday, October 4, 2010
ICFP, POPL
Back from ICFP, and slowly getting resettled. I'll be writing about the conference soon!
Meanwhile, I'm very happy to report that my paper with Mitch Wand, A separation logic for refining concurrent objects, has been accepted for publication in POPL 2011. You can find a draft of the paper here.
Meanwhile, I'm very happy to report that my paper with Mitch Wand, A separation logic for refining concurrent objects, has been accepted for publication in POPL 2011. You can find a draft of the paper here.
Abstract. Fine-grained concurrent data structures are crucial for gaining performance from multiprocessing, but their design is a subtle art. Recent literature has made large strides in verifying these data structures, using either atomicity refinement or separation logic with rely-guarantee reasoning. In this paper we show how the ownership discipline of separation logic can be used to enable atomicity refinement, and we develop a new rely-guarantee method that is localized to the definition of a data structure. We present the first semantics of separation logic that is sensitive to atomicity, and show how to control this sensitivity through ownership. The result is a logic that enables compositional reasoning about atomicity and interference, even for programs that use fine-grained synchronization and dynamic memory allocation.
Wednesday, September 22, 2010
The join calculus
How do you solve the dining philosopher's problem in your favorite concurrency paradigm? Can you do it in a decentralized way, so that philosophers desiring unrelated chopsticks never get in each other's way?
The join calculus, originally developed for distributed programming, offers a truly elegant solution to this classic concurrency problem. In fact, the solution requires little more than stating the problem:
This bit of pseudocode treats each chopstick as a separate channel, and also uses channels to represent requests for chopsticks (hungry). There are a collection of joins, which provide an event handler that should fire when messages are available on a given set of channels. All the relevant messages are removed from their queues in a single atomic step.
Aside from a few important details (e.g. are channels synchronous? it depends), that example provides a pretty complete picture of what the join calculus offers. It's possible to code up solutions to a number of classic problems in a similarly succinct way: reader-writer locks, barriers, condition variables, semaphores, Santa Claus...
Of course, many synchronization constructs (even the lowly lock) are capable of encoding a large variety of other constructs, though perhaps not as elegantly. The real question is whether such encodings provide the same parallel scalability that a direct solution does.
To answer this question for the join-based encodings, we need to know how joins are implemented. An implementation must provide the atomicity guarantee described above, and every implementation I'm aware of does this by using a single lock per group of joined channels. This centralized lock destroys scalability because it sequentializes use of the channels and firing of events. In the case of the dining philosophers, it means that two philosophers sitting far from one another must still contend for the same lock before picking up their independent chopsticks.
I've been working on an algorithm and implementation that allows for a much finer grain of concurrency. Stay tuned...
The join calculus, originally developed for distributed programming, offers a truly elegant solution to this classic concurrency problem. In fact, the solution requires little more than stating the problem:
channel hungry[1..n]
channel chops[1..n]
when hungry[1], chops[1], chops[2] do
eat(1); chops[1]; chops[2]; think(1); hungry[1]
...
when hungry[n], chops[n], chops[1] do
eat(n); chops[n]; chops[1]; think(n); hungry[1]
initially
hungry[1] ; ... ; hungry[n]
chops[1] ; ... ; chops[n]This bit of pseudocode treats each chopstick as a separate channel, and also uses channels to represent requests for chopsticks (hungry). There are a collection of joins, which provide an event handler that should fire when messages are available on a given set of channels. All the relevant messages are removed from their queues in a single atomic step.
Aside from a few important details (e.g. are channels synchronous? it depends), that example provides a pretty complete picture of what the join calculus offers. It's possible to code up solutions to a number of classic problems in a similarly succinct way: reader-writer locks, barriers, condition variables, semaphores, Santa Claus...
Of course, many synchronization constructs (even the lowly lock) are capable of encoding a large variety of other constructs, though perhaps not as elegantly. The real question is whether such encodings provide the same parallel scalability that a direct solution does.
To answer this question for the join-based encodings, we need to know how joins are implemented. An implementation must provide the atomicity guarantee described above, and every implementation I'm aware of does this by using a single lock per group of joined channels. This centralized lock destroys scalability because it sequentializes use of the channels and firing of events. In the case of the dining philosophers, it means that two philosophers sitting far from one another must still contend for the same lock before picking up their independent chopsticks.
I've been working on an algorithm and implementation that allows for a much finer grain of concurrency. Stay tuned...
Tuesday, September 21, 2010
ICFP pregame: Reduceron
Some PRL members have been meeting to discuss ICFP papers prior to the conference. Since we worked hard to grok the essence of each, it seems worth posting that here.
The Reduceron Reconfigured
Matthew Naylor and Colin Runciman
Long ago (the '80s) there was a great deal of interest in building architecture geared toward functional languages (taking Backus's Turing Lecture literally). These efforts burned out, though, because industry heavyweights were able to make unsurpassable progress with traditional von Neumann machines.
This paper revisits functional architecture in the world of FPGAs. I can't say how much their architecture differs from those proposed in the '80s, but the big emphasis in the paper is on a certain kind of parallelism. This parallelism stems from the purity of the language, but not in the way you might think: it is not at the level of program expressions but at the level of instructions.
How do you execute a beta-reduction with several arguments? On a von Neumann architecture, you do it in many sequential steps. The proposal here is to provide instructions that can, in a single cycle, execute such a beta-reduction. That single instruction interacts with memory in several ways: it loads the definition of the function, it pops the arguments off the stack, and it does appropriate pointer surgery to replace formals by actuals. In parallel, and in one step.
The paper proposes a compilation strategy and instruction set, and discusses an FPGA implementation. On the benchmarks they give, the FPGA comes within an order of magnitude of GHC running on a modern Intel processor -- and the FPGA clocks 30x slower than the Intel. Given how much engineering has gone into GHC, that's pretty impressive.
A complaint: the takeaway wasn't clear. Even with their technique, the FPGA is a lot slower (in absolute terms) than what we have with GHC. So having an FPGA coprocessor, as they suggest, seems fruitless. Should we design ASICs along the lines of this paper?
The Reduceron Reconfigured
Matthew Naylor and Colin Runciman
Long ago (the '80s) there was a great deal of interest in building architecture geared toward functional languages (taking Backus's Turing Lecture literally). These efforts burned out, though, because industry heavyweights were able to make unsurpassable progress with traditional von Neumann machines.
This paper revisits functional architecture in the world of FPGAs. I can't say how much their architecture differs from those proposed in the '80s, but the big emphasis in the paper is on a certain kind of parallelism. This parallelism stems from the purity of the language, but not in the way you might think: it is not at the level of program expressions but at the level of instructions.
How do you execute a beta-reduction with several arguments? On a von Neumann architecture, you do it in many sequential steps. The proposal here is to provide instructions that can, in a single cycle, execute such a beta-reduction. That single instruction interacts with memory in several ways: it loads the definition of the function, it pops the arguments off the stack, and it does appropriate pointer surgery to replace formals by actuals. In parallel, and in one step.
The paper proposes a compilation strategy and instruction set, and discusses an FPGA implementation. On the benchmarks they give, the FPGA comes within an order of magnitude of GHC running on a modern Intel processor -- and the FPGA clocks 30x slower than the Intel. Given how much engineering has gone into GHC, that's pretty impressive.
A complaint: the takeaway wasn't clear. Even with their technique, the FPGA is a lot slower (in absolute terms) than what we have with GHC. So having an FPGA coprocessor, as they suggest, seems fruitless. Should we design ASICs along the lines of this paper?
Thursday, September 16, 2010
Shared-state versus message-passing
One of the most basic distinctions made in concurrency theory is between shared-state concurrency and message-passing concurrency. I'm finally getting around to reading John Reppy's book on Concurrent ML, and he has a succinct characterization of the two:
Shared-memory languages rely on imperative features ... for interprocess communication, and provide separate synchronization primitives. Message-passing languages provide a single unified mechanism for both synchronization and communication.
Tuesday, September 14, 2010
Hacking on, and with, Racket
Things have been a bit quiet on the research front: I've been doing a a bit of hacking and a lot of yak shaving.
Today's accomplishment: I've added a new primitive to Racket for compare-and-set. In hindsight, this is a pretty simple patch, maybe a couple-dozen lines. But getting there required some quality time with the 14Kloc jit.c file.
The upshot is that, with this patch, Racket can be used for writing non-blocking algorithms, modulo ongoing work to increase concurrency in its runtime system. I'm planning to design and build a comprehensive library for parallelism, inspired by java.util.concurrent but with somewhat different goals. I hope to have more to say about this soon.
Today's accomplishment: I've added a new primitive to Racket for compare-and-set. In hindsight, this is a pretty simple patch, maybe a couple-dozen lines. But getting there required some quality time with the 14Kloc jit.c file.
The upshot is that, with this patch, Racket can be used for writing non-blocking algorithms, modulo ongoing work to increase concurrency in its runtime system. I'm planning to design and build a comprehensive library for parallelism, inspired by java.util.concurrent but with somewhat different goals. I hope to have more to say about this soon.
Tuesday, September 7, 2010
Code → paper
I'm working on a paper where the main contribution is an algorithm, and the interesting aspect of the algorithm is not a complexity bound, or even a liveness property. Its appeal is harder to formalize: it enables fine-grained parallelism.
The evidence here is empirical, not theoretical. Consequently, when I started simplifying from real- to pseudo-code, my coauthor balked. There are at least two reasons pseudocode is a bad idea. First, it's easy to introduce mistakes. Second, it's a bit dishonest: your numbers relate to the real code, not a platonic version of it.
But there are good arguments in favor of pseudocode, too. In our case, it's relatively painless to treat the simplification I wanted to do as a refactoring of the real code -- so our library improves along the way. That's partly due to writing the code in a relatively high-level language. But in more complex, low-level cases, making the code presentable while keeping it executable could be much trickier, or even impossible.
What's a reasonable guideline for using pseudocode?
The evidence here is empirical, not theoretical. Consequently, when I started simplifying from real- to pseudo-code, my coauthor balked. There are at least two reasons pseudocode is a bad idea. First, it's easy to introduce mistakes. Second, it's a bit dishonest: your numbers relate to the real code, not a platonic version of it.
But there are good arguments in favor of pseudocode, too. In our case, it's relatively painless to treat the simplification I wanted to do as a refactoring of the real code -- so our library improves along the way. That's partly due to writing the code in a relatively high-level language. But in more complex, low-level cases, making the code presentable while keeping it executable could be much trickier, or even impossible.
What's a reasonable guideline for using pseudocode?
Wednesday, September 1, 2010
Specification safari: it's not fair
Lock-freedom is great: it guarantees that a system will make progress regardless of the vagaries of scheduling. The delay of one thread -- due to a cache miss, or I/O, or preemption -- doesn't force a delay on other threads. In practice, lock-free algorithms permit a greater degree of concurrency, and by Amdahl's law that translates to increased parallel speedup.
But what if we do know something about the scheduler? Most commonly, we know that the scheduler is fair. Fairness and lock-freedom seem orthogonal, since lock-freedom assumes nothing about the scheduler. So I was startled to realize that, in practice, the two properties do interact.
Most well-known lock-free algorithms do not preserve fairness! Concretely, if a thread using a lock-free queue calls enqueue, that call may never return, despite enqueue being a "nonblocking" operation. What gives?
The problem is that other threads in the system may be repeatedly competing to enqueue, a race-condition made safe by the fact that they're all using CAS to do this. But CAS does not guarantee fairness, so a thread can repeatedly lose the race. The scheduler has fulfilled its obligations, since the thread is continually given chances to try CAS. At one level of abstraction (the queue implementation), the thread is not being starved. But at a higher level of abstraction (the queue client), it is.
But what if we do know something about the scheduler? Most commonly, we know that the scheduler is fair. Fairness and lock-freedom seem orthogonal, since lock-freedom assumes nothing about the scheduler. So I was startled to realize that, in practice, the two properties do interact.
Most well-known lock-free algorithms do not preserve fairness! Concretely, if a thread using a lock-free queue calls enqueue, that call may never return, despite enqueue being a "nonblocking" operation. What gives?
The problem is that other threads in the system may be repeatedly competing to enqueue, a race-condition made safe by the fact that they're all using CAS to do this. But CAS does not guarantee fairness, so a thread can repeatedly lose the race. The scheduler has fulfilled its obligations, since the thread is continually given chances to try CAS. At one level of abstraction (the queue implementation), the thread is not being starved. But at a higher level of abstraction (the queue client), it is.
Monday, August 30, 2010
Specification safari: SOS and liveness
I've been thinking about specifications lately -- particularly for reactive systems, where you're more interested in ongoing interaction than a final result. There are a ton of competing approaches. But thanks to Lamport, we can at least separate safety requirements ("nothing bad happens") from liveness requirements ("something good keeps happening").
For my purposes, operational semantics is attractive for specifying safety: it's reasonable to think about what I'm doing in terms of abstract states and transitions, and the semantics nicely characterizes the permitted transitions.
But as it turns out, operational semantics specifies more than just safety properties. There's an implicit requirement that if the abstract machine can take a transition it must do so. You can see this if you try to design a machine that, from one state, nondeterministically (1) halts or (2) transitions to a different, final state. Try it: you can't do it! You have to add an auxiliary stuck state to signify halting.
This might seem like an obvious or trivial point. But it gets interesting once you realize that each transition in the operational semantics (the abstract machine) is likely to be realized by a large number of steps in the implementation (the concrete machine). In my case, the implementation of a single abstract step is given by a loop whose termination depends on progress of the system as a whole -- hardly trivial!
Operational semantics isn't saying everything I need to say, but it's coming a lot closer than I expected.
For my purposes, operational semantics is attractive for specifying safety: it's reasonable to think about what I'm doing in terms of abstract states and transitions, and the semantics nicely characterizes the permitted transitions.
But as it turns out, operational semantics specifies more than just safety properties. There's an implicit requirement that if the abstract machine can take a transition it must do so. You can see this if you try to design a machine that, from one state, nondeterministically (1) halts or (2) transitions to a different, final state. Try it: you can't do it! You have to add an auxiliary stuck state to signify halting.
This might seem like an obvious or trivial point. But it gets interesting once you realize that each transition in the operational semantics (the abstract machine) is likely to be realized by a large number of steps in the implementation (the concrete machine). In my case, the implementation of a single abstract step is given by a loop whose termination depends on progress of the system as a whole -- hardly trivial!
Operational semantics isn't saying everything I need to say, but it's coming a lot closer than I expected.
Saturday, August 28, 2010
Locking and liveness
I'm back in Boston, and rebooting the blog. I may eventually get back to the series on linear logic. But for now, I'm going to shoot for more bite-sized, self-contained posts.
I've been working on a highly-concurrent implementation of the join calculus, aiming to maximize parallelism. "Highly-concurrent" is often a euphemism for lock-avoiding. Since the whole point of locking is to serialize access to resources, locking destroys concurrency.
There's a nice formal characterization of lock avoidance, called obstruction freedom: if a thread is allowed to run in isolation, the thread will complete its task. In an obstruction-free system, threads can prevent progress only by continually interfering. Locks are ruled out because a lock held by one thread can passively prevent others from progressing.
Obstruction freedom is the weakest "nonblocking" progress condition. A stronger property is lock freedom, which says that the system makes progress in the presence of an arbitrary scheduler. Since the scheduler can run a thread in isolation, lock freedom implies obstruction freedom.
I believe my algorithm is free from deadlock and livelock -- assuming a fair scheduler. On the other hand, it is not obstruction free, much less lock free. Thus, although I do not use actual locks, my use of other synchronization mechanisms (read: CAS) is occasionally lock-like. I've minimized the likelihood of blocking, but it's still possible.
I'm left wondering: how important are these theoretical measures? I can see how to make the algorithm lock free, but it's a complicated change and likely to slow down the average case. Scientifically, I suppose there's only one answer: implement and compare.
I've been working on a highly-concurrent implementation of the join calculus, aiming to maximize parallelism. "Highly-concurrent" is often a euphemism for lock-avoiding. Since the whole point of locking is to serialize access to resources, locking destroys concurrency.
There's a nice formal characterization of lock avoidance, called obstruction freedom: if a thread is allowed to run in isolation, the thread will complete its task. In an obstruction-free system, threads can prevent progress only by continually interfering. Locks are ruled out because a lock held by one thread can passively prevent others from progressing.
Obstruction freedom is the weakest "nonblocking" progress condition. A stronger property is lock freedom, which says that the system makes progress in the presence of an arbitrary scheduler. Since the scheduler can run a thread in isolation, lock freedom implies obstruction freedom.
I believe my algorithm is free from deadlock and livelock -- assuming a fair scheduler. On the other hand, it is not obstruction free, much less lock free. Thus, although I do not use actual locks, my use of other synchronization mechanisms (read: CAS) is occasionally lock-like. I've minimized the likelihood of blocking, but it's still possible.
I'm left wondering: how important are these theoretical measures? I can see how to make the algorithm lock free, but it's a complicated change and likely to slow down the average case. Scientifically, I suppose there's only one answer: implement and compare.
Wednesday, June 2, 2010
Sequent calculus
This post is going to build on the idea of duality in logic to motivate the sequent calculus. To understand duality, we distinguished between two polarities, corresponding to either affirming or refuting a proposition, with negation moving between the two poles. Refuting a conjunction works like proving a disjunction, and so on.
As a first step toward sequent calculus, we alter notation, writing ⊢ A for ⊢ A aff and A ⊢ for ⊢ A ref. We then generalize in two ways. First, rather than a single formula A, we will allow a multiset of formulas Γ. The choice of multisets, rather than sets, is to allow for an analysis of structural rules later. The reading of ⊢ Γ is "some formula in Γ is affirmable" and similarly for Γ ⊢. This generalization is motivated by the need to internalize compound formulas into smaller pieces: there should be some relationship between ⊢ A ∨ B and ⊢ A, B (thanks, Neel, for that insight). Though, as we will see, this relationship is more subtle than it appears at first.
Once we allow multiple formulas on one side of the turnstile, though, we are forced to allow formulas on both sides. The culprit is the rule for negation -- even if we force its premise to stay on one side, its conclusion refuses to:
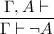
But now, our two judgments have become one! Instead of playing either as affirmer or refuter, we play as both at once. We will deduce sequents Γ ⊢ Δ, with the meaning that either some A ∈ Γ is refutable or some A ∈ Δ affirmable. The empty sequent ⊢ is, perforce, unprovable. The following rules, which determine the meaning of our three primary connectives, generalize our earlier rules to sequents:
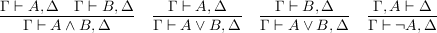
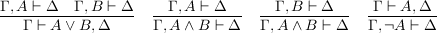
To bring the calculus to life, we need axioms -- and in fact, a single one will suffice:
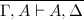
This rule has the somewhat startling reading "either A is refutable or it is affirmable," which makes it sound as if we have baked in classical principles from the start. But there is a somewhat Tarskian phenomenon here: our reading of the rule used the word "or" in a metalogical way, which has quite different force from the sequent ⊢ A ∨ ¬A. As it turns out, the axiom we have given occurs in both classic and intuitionistic sequent calculus.
With that, we have a complete kernel of sequent calculus. There is much more to say, of course. For instance, this calculus is classical, and making it intuitionistic is a matter of breaking the symmetry between affirmation and refutation, moving to sequents Γ ⊢ A. This situation stands in strong contrast to natural deduction, where the difference comes down to the inclusion of an axiom, rather than structural properties.
Girard discovered linear logic in part through an analysis what, precisely, must be restricted to get intuitionistic sequent calculus. His famous decomposition of intuitionistic implication, A → B = (!A) ⊸ B, tells us that the heart of the matter is restricting the structural rules (weakening and contraction, which we have baked in) for affirmation, but not for refutation. But there is an even deeper story, based on polarity, which will allow us to view classical logic through a constructive lens...
As a first step toward sequent calculus, we alter notation, writing ⊢ A for ⊢ A aff and A ⊢ for ⊢ A ref. We then generalize in two ways. First, rather than a single formula A, we will allow a multiset of formulas Γ. The choice of multisets, rather than sets, is to allow for an analysis of structural rules later. The reading of ⊢ Γ is "some formula in Γ is affirmable" and similarly for Γ ⊢. This generalization is motivated by the need to internalize compound formulas into smaller pieces: there should be some relationship between ⊢ A ∨ B and ⊢ A, B (thanks, Neel, for that insight). Though, as we will see, this relationship is more subtle than it appears at first.
Once we allow multiple formulas on one side of the turnstile, though, we are forced to allow formulas on both sides. The culprit is the rule for negation -- even if we force its premise to stay on one side, its conclusion refuses to:
But now, our two judgments have become one! Instead of playing either as affirmer or refuter, we play as both at once. We will deduce sequents Γ ⊢ Δ, with the meaning that either some A ∈ Γ is refutable or some A ∈ Δ affirmable. The empty sequent ⊢ is, perforce, unprovable. The following rules, which determine the meaning of our three primary connectives, generalize our earlier rules to sequents:
To bring the calculus to life, we need axioms -- and in fact, a single one will suffice:
This rule has the somewhat startling reading "either A is refutable or it is affirmable," which makes it sound as if we have baked in classical principles from the start. But there is a somewhat Tarskian phenomenon here: our reading of the rule used the word "or" in a metalogical way, which has quite different force from the sequent ⊢ A ∨ ¬A. As it turns out, the axiom we have given occurs in both classic and intuitionistic sequent calculus.
With that, we have a complete kernel of sequent calculus. There is much more to say, of course. For instance, this calculus is classical, and making it intuitionistic is a matter of breaking the symmetry between affirmation and refutation, moving to sequents Γ ⊢ A. This situation stands in strong contrast to natural deduction, where the difference comes down to the inclusion of an axiom, rather than structural properties.
Girard discovered linear logic in part through an analysis what, precisely, must be restricted to get intuitionistic sequent calculus. His famous decomposition of intuitionistic implication, A → B = (!A) ⊸ B, tells us that the heart of the matter is restricting the structural rules (weakening and contraction, which we have baked in) for affirmation, but not for refutation. But there is an even deeper story, based on polarity, which will allow us to view classical logic through a constructive lens...
Sunday, May 30, 2010
The Zipper
In talking about destination passing style, I mentioned that a basic difficulty in purely functional programming is that data structures must be built bottom-up and traversed top-down. Huet's zipper is a functional data structure that allows more flexible navigation and functional alteration.
Zippers are best illustrated on a data structure more complicated than lists, so we'll look at binary trees with Nat-labeled leaves:
Tree ::= Leaf Nat | Branch Tree Tree
We want to be able to navigate up and down within a tree, while functionally updating it, and without starting from the top every time. First, imagine we have a cursor somewhere in the tree, from which we can navigate in any direction, or functionally update the tree under the cursor. We can represent this situation by separating the tree into two parts: a tree context (a tree with a hole), representing the tree above the cursor, and a tree, representing the tree under the cursor.
TreeCtx ::= Hole | Left TreeCtx Tree | Right Tree TreeCtx
Cursor = TreeCtx * Tree
It should be clear that given a cursor, we can "plug the hole" to get the full tree back, forgetting where we were focusing within it. A cursor gives us a way to track our location within a tree, but navigating upwards into the tree is still expensive, because we must navigate the context from top down.
The next trick will be familiar to anyone who has seen frame stacks and the CK machine. We can define
TreeFrame ::= LFrame Tree | RFrame Tree
FrameStack = List(TreeFrame)
and observe that the types TreeCtx and FrameStack are isomorphic. Now that we've recognized contexts as a list of frames, though, we can further recognize that we can keep this list in reverse order. That way, traversing the list top down amounts to traversing the context bottom up.
Zipper = FrameStack * Tree
goUp (Nil, _) = Error "Already at top"
goUp (Cons (LFrame t) fs, u) = (fs, Branch u t)
goUp (Cons (RFrame t) fs, u) = (fs, Branch t u)
goDownLeft (fs, Leaf _) = Error "At leaf"
goDownLeft (fs, Branch t u) = (Cons (LFrame u) fs, t)
goDownRight (fs, Leaf _) = Error "At leaf"
goDownRight (fs, Branch t u) = (Cons (RFrame t) fs, u)
update (fs, _) t = (fs, t)
All of these operations take constant time; they also all implicitly involve allocation. The data structure is called the "zipper" because moving up and down the tree is analagous to moving a zipper up and down its tracks.
There is a close relationship to Deutsch-Schorr-Waite (pointer-reversing) algorithms, which can be understood as the imperative counterpart to the zipper. Finally, one of the neat things about zippers is that they can be generated in a uniform way for most data structures we use in functional programming -- and this is done through an analog to derivatives, applied at the level of types! See Conor McBride's page for the details.
Zippers are best illustrated on a data structure more complicated than lists, so we'll look at binary trees with Nat-labeled leaves:
Tree ::= Leaf Nat | Branch Tree Tree
We want to be able to navigate up and down within a tree, while functionally updating it, and without starting from the top every time. First, imagine we have a cursor somewhere in the tree, from which we can navigate in any direction, or functionally update the tree under the cursor. We can represent this situation by separating the tree into two parts: a tree context (a tree with a hole), representing the tree above the cursor, and a tree, representing the tree under the cursor.
TreeCtx ::= Hole | Left TreeCtx Tree | Right Tree TreeCtx
Cursor = TreeCtx * Tree
It should be clear that given a cursor, we can "plug the hole" to get the full tree back, forgetting where we were focusing within it. A cursor gives us a way to track our location within a tree, but navigating upwards into the tree is still expensive, because we must navigate the context from top down.
The next trick will be familiar to anyone who has seen frame stacks and the CK machine. We can define
TreeFrame ::= LFrame Tree | RFrame Tree
FrameStack = List(TreeFrame)
and observe that the types TreeCtx and FrameStack are isomorphic. Now that we've recognized contexts as a list of frames, though, we can further recognize that we can keep this list in reverse order. That way, traversing the list top down amounts to traversing the context bottom up.
Zipper = FrameStack * Tree
goUp (Nil, _) = Error "Already at top"
goUp (Cons (LFrame t) fs, u) = (fs, Branch u t)
goUp (Cons (RFrame t) fs, u) = (fs, Branch t u)
goDownLeft (fs, Leaf _) = Error "At leaf"
goDownLeft (fs, Branch t u) = (Cons (LFrame u) fs, t)
goDownRight (fs, Leaf _) = Error "At leaf"
goDownRight (fs, Branch t u) = (Cons (RFrame t) fs, u)
update (fs, _) t = (fs, t)
All of these operations take constant time; they also all implicitly involve allocation. The data structure is called the "zipper" because moving up and down the tree is analagous to moving a zipper up and down its tracks.
There is a close relationship to Deutsch-Schorr-Waite (pointer-reversing) algorithms, which can be understood as the imperative counterpart to the zipper. Finally, one of the neat things about zippers is that they can be generated in a uniform way for most data structures we use in functional programming -- and this is done through an analog to derivatives, applied at the level of types! See Conor McBride's page for the details.
Sunday, May 23, 2010
Duality in logic
If you've seen logic, you've seen the De Morgan laws:
¬(A ∧ B) ⇔ ¬ A ∨ ¬ B
¬(A ∨ B) ⇔ ¬ A ∧ ¬ B
and similarly for quantifiers. We often say that ∧ and ∨ are "De Morgan duals" to each other. In classical logic we also have
A ⇔ ¬ ¬ A
which is to say ¬ is an involution.
In this post, I want to emphasize a certain perspective on negation that gives a nice reading to De Morgan duality. This perspective shouldn't be too surprising, but making it explicit will be helpful for upcoming posts. What I'm going to do is split the judgment ⊢ A, which represents an assertion that A is true, into two judgments:
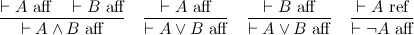
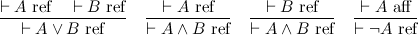
The two judgments are affirmation and refutation, respectively. Thus we've put truth and falsehood on common footing, and in particular, we can construct a direct refutation of a proposition. For instance, to refute A ∧ B is to refute either of A or B.
These two judgments capture the essence of both De Morgan duality, and the involutive nature of negation. The point is that conjunction and disjunction are two sides of the same coin, the difference being whether you are affirming or refuting a proposition. Negation switches between the two modes of proof, and because there are only two modes, it is an involution.
In general, we can distinguish between positive and negative polarities, so that affirmation is positive and refutation negative. Polarities show up all over the place. A common example is game semantics, where the validity of a proposition is modeled by the player (trying to affirm it) has a winning strategy against the opponent (trying to refute it). Polarity, it turns out, is also very important in understanding linear logic; stay tuned.
¬(A ∧ B) ⇔ ¬ A ∨ ¬ B
¬(A ∨ B) ⇔ ¬ A ∧ ¬ B
and similarly for quantifiers. We often say that ∧ and ∨ are "De Morgan duals" to each other. In classical logic we also have
A ⇔ ¬ ¬ A
which is to say ¬ is an involution.
In this post, I want to emphasize a certain perspective on negation that gives a nice reading to De Morgan duality. This perspective shouldn't be too surprising, but making it explicit will be helpful for upcoming posts. What I'm going to do is split the judgment ⊢ A, which represents an assertion that A is true, into two judgments:
The two judgments are affirmation and refutation, respectively. Thus we've put truth and falsehood on common footing, and in particular, we can construct a direct refutation of a proposition. For instance, to refute A ∧ B is to refute either of A or B.
These two judgments capture the essence of both De Morgan duality, and the involutive nature of negation. The point is that conjunction and disjunction are two sides of the same coin, the difference being whether you are affirming or refuting a proposition. Negation switches between the two modes of proof, and because there are only two modes, it is an involution.
In general, we can distinguish between positive and negative polarities, so that affirmation is positive and refutation negative. Polarities show up all over the place. A common example is game semantics, where the validity of a proposition is modeled by the player (trying to affirm it) has a winning strategy against the opponent (trying to refute it). Polarity, it turns out, is also very important in understanding linear logic; stay tuned.
Saturday, May 22, 2010
Weak normalization, cut elimination, and consistency
Suppose you have a notion of reduction on terms, M → N. Then M is a normal form if there is no N such that M → N; that is, no further steps from M are possible. We say that → is (weakly) normalizing if every M can take some number of steps to reach a normal form, and strongly normalizing if no M can take an infinite number of steps. In other words, weak normalization means that every term can terminate, while strong normalization means that every term must terminate. Notice that strong normalization implies weak normalization.
STLC, System F, CoC, LF, ... are all strongly normalizing. When we view these systems as logics, this property is often considered crucial; why?
The reason is simple: weak normalization suffices to show consistency. Let's take consistency to mean that False is not provable, which in this setting means that there is no term M of type False. The line of reasoning goes something like:
which means that False is unprovable. In the fourth step, we rely on the fact that we can give a simple, inductive characterization of the normal forms in the calculus that are clearly not typeable by False. Whereas this fact about terms in general is much harder to show directly.
In a sequent presentation, cut elimination corresponds to weak normalization: for every proof, there exists some cut-free proof of the same theorem. Again, the theorem is useful because cut-free proofs have good properties that are easy to demonstrate. In particular, they often enjoy the subformula property, which says that any cut-free proof of Γ ⊢ Δ contains only subformulas of Γ and Δ.
As a sidenote, weak normalization does not appear to be necessary for consistency. Take STLC, in which A ⇒ A is certainly provable. Adding a constant Loop : A ⇒ A such that Loop → Loop does not affect consistency, but breaks weak normalization.
STLC, System F, CoC, LF, ... are all strongly normalizing. When we view these systems as logics, this property is often considered crucial; why?
The reason is simple: weak normalization suffices to show consistency. Let's take consistency to mean that False is not provable, which in this setting means that there is no term M of type False. The line of reasoning goes something like:
- Suppose M has type τ.
- By weak normalization, M →* N for some normal form N.
- By type preservation, N also has type τ.
- "Obviously", no normal form has type False.
- Thus, τ cannot be False.
which means that False is unprovable. In the fourth step, we rely on the fact that we can give a simple, inductive characterization of the normal forms in the calculus that are clearly not typeable by False. Whereas this fact about terms in general is much harder to show directly.
In a sequent presentation, cut elimination corresponds to weak normalization: for every proof, there exists some cut-free proof of the same theorem. Again, the theorem is useful because cut-free proofs have good properties that are easy to demonstrate. In particular, they often enjoy the subformula property, which says that any cut-free proof of Γ ⊢ Δ contains only subformulas of Γ and Δ.
As a sidenote, weak normalization does not appear to be necessary for consistency. Take STLC, in which A ⇒ A is certainly provable. Adding a constant Loop : A ⇒ A such that Loop → Loop does not affect consistency, but breaks weak normalization.
Staying grounded in Haskell
I want to look a bit closer at the question: are λx.Ω x and Ω observationally equivalent? In a CBV language, they are clearly distinguishable by a context of type unit:
(λf.()) []
Plugging in the first term gives a terminating program, while the second program leads to divergence. This behavior follows from two properties of CBV evaluation: arguments are evaluated before substitution, and λ-abstractions count as values (i.e., we do not evaluate under a λ). It follows that, for CBV languages, observational equivalence is robust under different choices of observable types (base types, function types, etc.).
In a CBN language, the above context does not serve to distinguish the two terms, as f is not forced by applying it to some argument. But of course, the terms λx.Ω x and Ω themselves have different behavior under evaluation, because just as in CBV, λ-abstractions are considered values. So for CBN, observational equivalence is not robust: the types you choose to observe matter.
In the last post on this topic, I raised the natural question for a lazy language: how should you choose the observable types?
Haskell, it turns out, has a rather satisfying answer to this question. Haskell programs are allowed to have essentially one of two types: t or IO t, for any type t implementing Show. Both are allowed at the REPL in ghci, but a compiled program must have a main function of, roughly, type IO ().
The Show typeclass requires, in particular, a show function of type t -> String. The REPL essentially wraps a call to show around any expression the user enters. As a result, the REPL only allows observation at one ground type, String. Compiled programs are even simpler: they must produce a value of unit type, and are evaluated only for effect. So again we are observing at a ground type, unit, modulo side-effects.
As a result, I believe that λx.Ω x and Ω are observationally equivalent in Haskell.
What about untyped, lazy languages? There, I think, you have no choice but to allow observation at "any type", and hence to distinguish the two terms. In operational terms, an expression at the REPL would have to be evaluated far enough to figure out whether it was a string (or other printable type) or something else -- which, alas, is too much to ask for Ω.
(λf.()) []
Plugging in the first term gives a terminating program, while the second program leads to divergence. This behavior follows from two properties of CBV evaluation: arguments are evaluated before substitution, and λ-abstractions count as values (i.e., we do not evaluate under a λ). It follows that, for CBV languages, observational equivalence is robust under different choices of observable types (base types, function types, etc.).
In a CBN language, the above context does not serve to distinguish the two terms, as f is not forced by applying it to some argument. But of course, the terms λx.Ω x and Ω themselves have different behavior under evaluation, because just as in CBV, λ-abstractions are considered values. So for CBN, observational equivalence is not robust: the types you choose to observe matter.
In the last post on this topic, I raised the natural question for a lazy language: how should you choose the observable types?
Haskell, it turns out, has a rather satisfying answer to this question. Haskell programs are allowed to have essentially one of two types: t or IO t, for any type t implementing Show. Both are allowed at the REPL in ghci, but a compiled program must have a main function of, roughly, type IO ().
The Show typeclass requires, in particular, a show function of type t -> String. The REPL essentially wraps a call to show around any expression the user enters. As a result, the REPL only allows observation at one ground type, String. Compiled programs are even simpler: they must produce a value of unit type, and are evaluated only for effect. So again we are observing at a ground type, unit, modulo side-effects.
As a result, I believe that λx.Ω x and Ω are observationally equivalent in Haskell.
What about untyped, lazy languages? There, I think, you have no choice but to allow observation at "any type", and hence to distinguish the two terms. In operational terms, an expression at the REPL would have to be evaluated far enough to figure out whether it was a string (or other printable type) or something else -- which, alas, is too much to ask for Ω.
Saturday, May 15, 2010
Destination-passing style
Every functional programmer knows that tail-recursion is desirable: it turns recursion (in the stack-growing sense) into iteration (in the goto sense).
It's also well-known that transforming a function into continuation-passing style (CPS) makes it tail-recursive. Take, for example, the append function:
append [] ys = ys
append x::xs ys = x::(append xs ys)
appendCPS [] ys k = k ys
appendCPS x::xs ys k = appendCPS xs ys (λzs. k (x::zs))
appendCPS is tail-recursive, but only because we've cheated: as its goto-based loop iterates, it allocates a closure per element of xs, essentially recording in the heap what append would've allocated on the stack.
A standard trick is to write in accumulator-passing style, which can be thought of as specializing the representation of continuations in CPS. I invite you to try this for append. A hint: there is a reason that revAppend is a common library function.
Sadly, there is a general pattern here. When we want to iterate through a list from left to right, we end up accumulating the elements of the list in the reverse order. The essential problem is that basic functional data structures can only be built bottom up, and only traversed top down. Of course one can use more complex functional data structures, like Huet's zipper, to do better, but we'd like to program efficiently with simple lists.
In a 1998 paper, Yasuhiko Minamide studied an idea that has come to be known as "destination-passing style". Consider a continuation λx.cons 1 x which, when applied, allocates a cons cell. The representation of this continuation is a closure. But this is a bit silly. If we are writing in CPS, we allocate a closure whose sole purpose is to remind us to allocate a cons cell later. Why not allocate the cons cell in the first place? Then, instead of passing a closure, we can pass the location for the cdr, which eventually gets written with the final value x. Hence, destination-passing style.
The fact that the cdr of the cons cell gets clobbered means that the cons cell must be unaliased until "applied" to a final value. Hence Minamide imposes a linear typing discipline on such values.
The other important ingredient is composition: we want to be able to compose λx.cons 1 x with λx.cons 2 x to get λx.cons 1 (cons 2 x). To accomplish this, our representation will consist of two pointers, one to the top of the data structure, and one to the hole in the data structure (the destination). With that representation, composition is accomplished with just a bit of pointer stitching. The destination of the cons 1 cell gets clobbered with a pointer to the cons 2 cell, the new hole is the cons 2 cell's hole, and the top of the data structure is the top of the cons 1 cell.
Here is append in destination-passing style:
appendDPS [] ys dk = fill dk ys
appendDPS x::xs ys dk = appendDPS xs ys (comp dk (dcons x))
where fill dk ys plugs ys into its destination (the hole in dk), comp composes two destinations, and dcons x creates a cons cell with car x and cdr its destination. These combinators allow us to construct lists in a top-down fashion, matching the top-down way we consume them.
It's also well-known that transforming a function into continuation-passing style (CPS) makes it tail-recursive. Take, for example, the append function:
append [] ys = ys
append x::xs ys = x::(append xs ys)
appendCPS [] ys k = k ys
appendCPS x::xs ys k = appendCPS xs ys (λzs. k (x::zs))
appendCPS is tail-recursive, but only because we've cheated: as its goto-based loop iterates, it allocates a closure per element of xs, essentially recording in the heap what append would've allocated on the stack.
A standard trick is to write in accumulator-passing style, which can be thought of as specializing the representation of continuations in CPS. I invite you to try this for append. A hint: there is a reason that revAppend is a common library function.
Sadly, there is a general pattern here. When we want to iterate through a list from left to right, we end up accumulating the elements of the list in the reverse order. The essential problem is that basic functional data structures can only be built bottom up, and only traversed top down. Of course one can use more complex functional data structures, like Huet's zipper, to do better, but we'd like to program efficiently with simple lists.
In a 1998 paper, Yasuhiko Minamide studied an idea that has come to be known as "destination-passing style". Consider a continuation λx.cons 1 x which, when applied, allocates a cons cell. The representation of this continuation is a closure. But this is a bit silly. If we are writing in CPS, we allocate a closure whose sole purpose is to remind us to allocate a cons cell later. Why not allocate the cons cell in the first place? Then, instead of passing a closure, we can pass the location for the cdr, which eventually gets written with the final value x. Hence, destination-passing style.
The fact that the cdr of the cons cell gets clobbered means that the cons cell must be unaliased until "applied" to a final value. Hence Minamide imposes a linear typing discipline on such values.
The other important ingredient is composition: we want to be able to compose λx.cons 1 x with λx.cons 2 x to get λx.cons 1 (cons 2 x). To accomplish this, our representation will consist of two pointers, one to the top of the data structure, and one to the hole in the data structure (the destination). With that representation, composition is accomplished with just a bit of pointer stitching. The destination of the cons 1 cell gets clobbered with a pointer to the cons 2 cell, the new hole is the cons 2 cell's hole, and the top of the data structure is the top of the cons 1 cell.
Here is append in destination-passing style:
appendDPS [] ys dk = fill dk ys
appendDPS x::xs ys dk = appendDPS xs ys (comp dk (dcons x))
where fill dk ys plugs ys into its destination (the hole in dk), comp composes two destinations, and dcons x creates a cons cell with car x and cdr its destination. These combinators allow us to construct lists in a top-down fashion, matching the top-down way we consume them.
Wednesday, May 12, 2010
Staying grounded
Observational equivalence is a cornerstone of semantics: given a notion of observations on complete "programs", you get a notion of equivalence on program fragments. Two fragments are equivalent if no program context they are placed into leads to distinct observations. Contexts transform internal observations, made within the language, to external observations, made by some putative user of the language.
Usually, we can be loose with what we consider an observation. The canonical observation is program termination: a one bit observation. This is equivalent to observing actual values at ground type, since the context
if [] = c then () else diverge
transforms value observations to termination observations.
So let's take termination as the basic observable. It turns out that, as least for call-by-name, it makes a difference where termination is observed: at ground type only, or at all types? Using the former, the programs λx.Ω and Ω are equated, because any CBN ground type context that uses them must apply them to an argument, in both cases leading to divergence. If, on the other hand, we observe termination at all types, then the context [] serves to distinguish them, since the first terminates and the second doesn't. Cf. Abramsky's work with lazy lambda calculus.
I'm curious about the methodological implications. An interpreter for Haskell based on ground equivalence could substitute Ω for λx.Ω, which means a user could type λx.Ω into the REPL and never get an answer. That seems wrong, or at least odd -- but do we care? Do we give up useful equations by observing at all types?
Update: clarified that the above remarks are specific to a CBN evaluation strategy.
Call-by-name, call-by-value, and the linear lambda calculus
I've started work at MSRC, and one of my immediate goals is to get better acquainted with the linear λ-calculus. Girard's linear logic is the archetypical substructural logic: a proof of a linear implication A ⊸ B is a proof of B that uses the assumption A exactly once. The logic is substructural because it lacks two of the "structural rules", namely contraction and weakening, that would permit assumptions to be duplicated or thrown away, respectively. On the other hand, linear logic includes a modality ! (read "of course") under which the structural rules hold. Thus you can prove that !A ⊸ (!B ⊸ !A), throwing away the assumption about B.
Linear logic, via Curry-Howard, begets linear λ-calculus. Here's a simple implicational version:
There is an interesting and natural operational semantics for this calculus, where functions have a call-by-value (CBV) semantics and lets have a call-by-name (CBN) semantics. Rather than exploring that design choice, however, I want to talk about one way to exploit it.
It turns out that intuitionistic logic (IL) embeds, in a certain sense, into intuitionistic linear logic (ILL). The most well-known embedding is (A → B)* = !A* ⊸ B*, so that A is valid in IL iff A* is valid in ILL. The intuition is simple: a proof in IL is just a linear proof in which every assumption is treated structurally. Other embeddings are possible; I'm going to use (A → B)* = !(A* ⊸ B*), for reasons that will become clear momentarily.
The connection between IL and ILL propositions raises a question from the Curry-Howard perspective: can we embed λ-calculus terms into linear λ-calculus terms, such that their types follow the * embedding above? The answer is yes -- and more. Just as Plotkin gave two CPS transformations, corresponding to CBV and CBN semantics, we can map λ-calculus into linear λ-calculus in two ways, again preserving CBV and CBN semantics.
First, the CBV version:
The first thing to notice about this translation is that !-introduction is used only around CBV values (variables and lambdas). Thus the CBN semantics of !-elimination never causes trouble. Variables can be !-ed because they will always be let-bound in this translation. On the other hand, the CBV semantics of linear functions means that in the application M N, the translated argument N* will be evaluated to some !L before substitution -- and, as we already mentioned, L can by construction only be a value. Note that the let-bindings in the translation are not used to force evaluation--after all, they are CBN!--but simply to eliminate the ! that we are wrapping around every value.
The CBN translation differs only in the rule for application:
These translations are adapted from Maraist et al, who attribute them to Girard. I changed the CBN translation, however, to ease comparison to the CBV translation.
Linear logic, via Curry-Howard, begets linear λ-calculus. Here's a simple implicational version:
M ::= x | λx.M | M N | !M let !x = M in Nwhere o is a base type. When a variable x is bound by a λ, it must be used exactly once in the body. When it is bound in a let, it can be used freely in the body. The catch is that in let !x = M in N, M must be of type !τ. Expressions of type !τ are introduced as !M, where M can only mention let-bound variables.
τ ::= o | τ ⊸ τ | !τ
There is an interesting and natural operational semantics for this calculus, where functions have a call-by-value (CBV) semantics and lets have a call-by-name (CBN) semantics. Rather than exploring that design choice, however, I want to talk about one way to exploit it.
It turns out that intuitionistic logic (IL) embeds, in a certain sense, into intuitionistic linear logic (ILL). The most well-known embedding is (A → B)* = !A* ⊸ B*, so that A is valid in IL iff A* is valid in ILL. The intuition is simple: a proof in IL is just a linear proof in which every assumption is treated structurally. Other embeddings are possible; I'm going to use (A → B)* = !(A* ⊸ B*), for reasons that will become clear momentarily.
The connection between IL and ILL propositions raises a question from the Curry-Howard perspective: can we embed λ-calculus terms into linear λ-calculus terms, such that their types follow the * embedding above? The answer is yes -- and more. Just as Plotkin gave two CPS transformations, corresponding to CBV and CBN semantics, we can map λ-calculus into linear λ-calculus in two ways, again preserving CBV and CBN semantics.
First, the CBV version:
x* = !x
(λx.M)* = !(λy.let !x = y in M*)
(M N)* = (let !z = M* in z) N*
The first thing to notice about this translation is that !-introduction is used only around CBV values (variables and lambdas). Thus the CBN semantics of !-elimination never causes trouble. Variables can be !-ed because they will always be let-bound in this translation. On the other hand, the CBV semantics of linear functions means that in the application M N, the translated argument N* will be evaluated to some !L before substitution -- and, as we already mentioned, L can by construction only be a value. Note that the let-bindings in the translation are not used to force evaluation--after all, they are CBN!--but simply to eliminate the ! that we are wrapping around every value.
The CBN translation differs only in the rule for application:
Here again, the lets are just being used to unpack !-ed values. The significant change is the introduction of a ! around the translation of N: it has the effect of suspending the computation of the argument, because in linear λ-calculus, !M is a value.(M N)* = (let !z = M* in z) !(let !z = N* in z)
These translations are adapted from Maraist et al, who attribute them to Girard. I changed the CBN translation, however, to ease comparison to the CBV translation.
Subscribe to:
Posts (Atom)
