In talking about destination passing style, I mentioned that a basic difficulty in purely functional programming is that data structures must be built bottom-up and traversed top-down. Huet's zipper is a functional data structure that allows more flexible navigation and functional alteration.
Zippers are best illustrated on a data structure more complicated than lists, so we'll look at binary trees with Nat-labeled leaves:
Tree ::= Leaf Nat | Branch Tree Tree
We want to be able to navigate up and down within a tree, while functionally updating it, and without starting from the top every time. First, imagine we have a cursor somewhere in the tree, from which we can navigate in any direction, or functionally update the tree under the cursor. We can represent this situation by separating the tree into two parts: a tree context (a tree with a hole), representing the tree above the cursor, and a tree, representing the tree under the cursor.
TreeCtx ::= Hole | Left TreeCtx Tree | Right Tree TreeCtx
Cursor = TreeCtx * Tree
It should be clear that given a cursor, we can "plug the hole" to get the full tree back, forgetting where we were focusing within it. A cursor gives us a way to track our location within a tree, but navigating upwards into the tree is still expensive, because we must navigate the context from top down.
The next trick will be familiar to anyone who has seen frame stacks and the CK machine. We can define
TreeFrame ::= LFrame Tree | RFrame Tree
FrameStack = List(TreeFrame)
and observe that the types TreeCtx and FrameStack are isomorphic. Now that we've recognized contexts as a list of frames, though, we can further recognize that we can keep this list in reverse order. That way, traversing the list top down amounts to traversing the context bottom up.
Zipper = FrameStack * Tree
goUp (Nil, _) = Error "Already at top"
goUp (Cons (LFrame t) fs, u) = (fs, Branch u t)
goUp (Cons (RFrame t) fs, u) = (fs, Branch t u)
goDownLeft (fs, Leaf _) = Error "At leaf"
goDownLeft (fs, Branch t u) = (Cons (LFrame u) fs, t)
goDownRight (fs, Leaf _) = Error "At leaf"
goDownRight (fs, Branch t u) = (Cons (RFrame t) fs, u)
update (fs, _) t = (fs, t)
All of these operations take constant time; they also all implicitly involve allocation. The data structure is called the "zipper" because moving up and down the tree is analagous to moving a zipper up and down its tracks.
There is a close relationship to Deutsch-Schorr-Waite (pointer-reversing) algorithms, which can be understood as the imperative counterpart to the zipper. Finally, one of the neat things about zippers is that they can be generated in a uniform way for most data structures we use in functional programming -- and this is done through an analog to derivatives, applied at the level of types! See Conor McBride's page for the details.
Sunday, May 30, 2010
Sunday, May 23, 2010
Duality in logic
If you've seen logic, you've seen the De Morgan laws:
¬(A ∧ B) ⇔ ¬ A ∨ ¬ B
¬(A ∨ B) ⇔ ¬ A ∧ ¬ B
and similarly for quantifiers. We often say that ∧ and ∨ are "De Morgan duals" to each other. In classical logic we also have
A ⇔ ¬ ¬ A
which is to say ¬ is an involution.
In this post, I want to emphasize a certain perspective on negation that gives a nice reading to De Morgan duality. This perspective shouldn't be too surprising, but making it explicit will be helpful for upcoming posts. What I'm going to do is split the judgment ⊢ A, which represents an assertion that A is true, into two judgments:
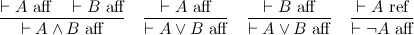
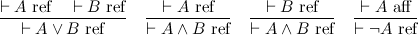
The two judgments are affirmation and refutation, respectively. Thus we've put truth and falsehood on common footing, and in particular, we can construct a direct refutation of a proposition. For instance, to refute A ∧ B is to refute either of A or B.
These two judgments capture the essence of both De Morgan duality, and the involutive nature of negation. The point is that conjunction and disjunction are two sides of the same coin, the difference being whether you are affirming or refuting a proposition. Negation switches between the two modes of proof, and because there are only two modes, it is an involution.
In general, we can distinguish between positive and negative polarities, so that affirmation is positive and refutation negative. Polarities show up all over the place. A common example is game semantics, where the validity of a proposition is modeled by the player (trying to affirm it) has a winning strategy against the opponent (trying to refute it). Polarity, it turns out, is also very important in understanding linear logic; stay tuned.
¬(A ∧ B) ⇔ ¬ A ∨ ¬ B
¬(A ∨ B) ⇔ ¬ A ∧ ¬ B
and similarly for quantifiers. We often say that ∧ and ∨ are "De Morgan duals" to each other. In classical logic we also have
A ⇔ ¬ ¬ A
which is to say ¬ is an involution.
In this post, I want to emphasize a certain perspective on negation that gives a nice reading to De Morgan duality. This perspective shouldn't be too surprising, but making it explicit will be helpful for upcoming posts. What I'm going to do is split the judgment ⊢ A, which represents an assertion that A is true, into two judgments:
The two judgments are affirmation and refutation, respectively. Thus we've put truth and falsehood on common footing, and in particular, we can construct a direct refutation of a proposition. For instance, to refute A ∧ B is to refute either of A or B.
These two judgments capture the essence of both De Morgan duality, and the involutive nature of negation. The point is that conjunction and disjunction are two sides of the same coin, the difference being whether you are affirming or refuting a proposition. Negation switches between the two modes of proof, and because there are only two modes, it is an involution.
In general, we can distinguish between positive and negative polarities, so that affirmation is positive and refutation negative. Polarities show up all over the place. A common example is game semantics, where the validity of a proposition is modeled by the player (trying to affirm it) has a winning strategy against the opponent (trying to refute it). Polarity, it turns out, is also very important in understanding linear logic; stay tuned.
Saturday, May 22, 2010
Weak normalization, cut elimination, and consistency
Suppose you have a notion of reduction on terms, M → N. Then M is a normal form if there is no N such that M → N; that is, no further steps from M are possible. We say that → is (weakly) normalizing if every M can take some number of steps to reach a normal form, and strongly normalizing if no M can take an infinite number of steps. In other words, weak normalization means that every term can terminate, while strong normalization means that every term must terminate. Notice that strong normalization implies weak normalization.
STLC, System F, CoC, LF, ... are all strongly normalizing. When we view these systems as logics, this property is often considered crucial; why?
The reason is simple: weak normalization suffices to show consistency. Let's take consistency to mean that False is not provable, which in this setting means that there is no term M of type False. The line of reasoning goes something like:
which means that False is unprovable. In the fourth step, we rely on the fact that we can give a simple, inductive characterization of the normal forms in the calculus that are clearly not typeable by False. Whereas this fact about terms in general is much harder to show directly.
In a sequent presentation, cut elimination corresponds to weak normalization: for every proof, there exists some cut-free proof of the same theorem. Again, the theorem is useful because cut-free proofs have good properties that are easy to demonstrate. In particular, they often enjoy the subformula property, which says that any cut-free proof of Γ ⊢ Δ contains only subformulas of Γ and Δ.
As a sidenote, weak normalization does not appear to be necessary for consistency. Take STLC, in which A ⇒ A is certainly provable. Adding a constant Loop : A ⇒ A such that Loop → Loop does not affect consistency, but breaks weak normalization.
STLC, System F, CoC, LF, ... are all strongly normalizing. When we view these systems as logics, this property is often considered crucial; why?
The reason is simple: weak normalization suffices to show consistency. Let's take consistency to mean that False is not provable, which in this setting means that there is no term M of type False. The line of reasoning goes something like:
- Suppose M has type τ.
- By weak normalization, M →* N for some normal form N.
- By type preservation, N also has type τ.
- "Obviously", no normal form has type False.
- Thus, τ cannot be False.
which means that False is unprovable. In the fourth step, we rely on the fact that we can give a simple, inductive characterization of the normal forms in the calculus that are clearly not typeable by False. Whereas this fact about terms in general is much harder to show directly.
In a sequent presentation, cut elimination corresponds to weak normalization: for every proof, there exists some cut-free proof of the same theorem. Again, the theorem is useful because cut-free proofs have good properties that are easy to demonstrate. In particular, they often enjoy the subformula property, which says that any cut-free proof of Γ ⊢ Δ contains only subformulas of Γ and Δ.
As a sidenote, weak normalization does not appear to be necessary for consistency. Take STLC, in which A ⇒ A is certainly provable. Adding a constant Loop : A ⇒ A such that Loop → Loop does not affect consistency, but breaks weak normalization.
Staying grounded in Haskell
I want to look a bit closer at the question: are λx.Ω x and Ω observationally equivalent? In a CBV language, they are clearly distinguishable by a context of type unit:
(λf.()) []
Plugging in the first term gives a terminating program, while the second program leads to divergence. This behavior follows from two properties of CBV evaluation: arguments are evaluated before substitution, and λ-abstractions count as values (i.e., we do not evaluate under a λ). It follows that, for CBV languages, observational equivalence is robust under different choices of observable types (base types, function types, etc.).
In a CBN language, the above context does not serve to distinguish the two terms, as f is not forced by applying it to some argument. But of course, the terms λx.Ω x and Ω themselves have different behavior under evaluation, because just as in CBV, λ-abstractions are considered values. So for CBN, observational equivalence is not robust: the types you choose to observe matter.
In the last post on this topic, I raised the natural question for a lazy language: how should you choose the observable types?
Haskell, it turns out, has a rather satisfying answer to this question. Haskell programs are allowed to have essentially one of two types: t or IO t, for any type t implementing Show. Both are allowed at the REPL in ghci, but a compiled program must have a main function of, roughly, type IO ().
The Show typeclass requires, in particular, a show function of type t -> String. The REPL essentially wraps a call to show around any expression the user enters. As a result, the REPL only allows observation at one ground type, String. Compiled programs are even simpler: they must produce a value of unit type, and are evaluated only for effect. So again we are observing at a ground type, unit, modulo side-effects.
As a result, I believe that λx.Ω x and Ω are observationally equivalent in Haskell.
What about untyped, lazy languages? There, I think, you have no choice but to allow observation at "any type", and hence to distinguish the two terms. In operational terms, an expression at the REPL would have to be evaluated far enough to figure out whether it was a string (or other printable type) or something else -- which, alas, is too much to ask for Ω.
(λf.()) []
Plugging in the first term gives a terminating program, while the second program leads to divergence. This behavior follows from two properties of CBV evaluation: arguments are evaluated before substitution, and λ-abstractions count as values (i.e., we do not evaluate under a λ). It follows that, for CBV languages, observational equivalence is robust under different choices of observable types (base types, function types, etc.).
In a CBN language, the above context does not serve to distinguish the two terms, as f is not forced by applying it to some argument. But of course, the terms λx.Ω x and Ω themselves have different behavior under evaluation, because just as in CBV, λ-abstractions are considered values. So for CBN, observational equivalence is not robust: the types you choose to observe matter.
In the last post on this topic, I raised the natural question for a lazy language: how should you choose the observable types?
Haskell, it turns out, has a rather satisfying answer to this question. Haskell programs are allowed to have essentially one of two types: t or IO t, for any type t implementing Show. Both are allowed at the REPL in ghci, but a compiled program must have a main function of, roughly, type IO ().
The Show typeclass requires, in particular, a show function of type t -> String. The REPL essentially wraps a call to show around any expression the user enters. As a result, the REPL only allows observation at one ground type, String. Compiled programs are even simpler: they must produce a value of unit type, and are evaluated only for effect. So again we are observing at a ground type, unit, modulo side-effects.
As a result, I believe that λx.Ω x and Ω are observationally equivalent in Haskell.
What about untyped, lazy languages? There, I think, you have no choice but to allow observation at "any type", and hence to distinguish the two terms. In operational terms, an expression at the REPL would have to be evaluated far enough to figure out whether it was a string (or other printable type) or something else -- which, alas, is too much to ask for Ω.
Saturday, May 15, 2010
Destination-passing style
Every functional programmer knows that tail-recursion is desirable: it turns recursion (in the stack-growing sense) into iteration (in the goto sense).
It's also well-known that transforming a function into continuation-passing style (CPS) makes it tail-recursive. Take, for example, the append function:
append [] ys = ys
append x::xs ys = x::(append xs ys)
appendCPS [] ys k = k ys
appendCPS x::xs ys k = appendCPS xs ys (λzs. k (x::zs))
appendCPS is tail-recursive, but only because we've cheated: as its goto-based loop iterates, it allocates a closure per element of xs, essentially recording in the heap what append would've allocated on the stack.
A standard trick is to write in accumulator-passing style, which can be thought of as specializing the representation of continuations in CPS. I invite you to try this for append. A hint: there is a reason that revAppend is a common library function.
Sadly, there is a general pattern here. When we want to iterate through a list from left to right, we end up accumulating the elements of the list in the reverse order. The essential problem is that basic functional data structures can only be built bottom up, and only traversed top down. Of course one can use more complex functional data structures, like Huet's zipper, to do better, but we'd like to program efficiently with simple lists.
In a 1998 paper, Yasuhiko Minamide studied an idea that has come to be known as "destination-passing style". Consider a continuation λx.cons 1 x which, when applied, allocates a cons cell. The representation of this continuation is a closure. But this is a bit silly. If we are writing in CPS, we allocate a closure whose sole purpose is to remind us to allocate a cons cell later. Why not allocate the cons cell in the first place? Then, instead of passing a closure, we can pass the location for the cdr, which eventually gets written with the final value x. Hence, destination-passing style.
The fact that the cdr of the cons cell gets clobbered means that the cons cell must be unaliased until "applied" to a final value. Hence Minamide imposes a linear typing discipline on such values.
The other important ingredient is composition: we want to be able to compose λx.cons 1 x with λx.cons 2 x to get λx.cons 1 (cons 2 x). To accomplish this, our representation will consist of two pointers, one to the top of the data structure, and one to the hole in the data structure (the destination). With that representation, composition is accomplished with just a bit of pointer stitching. The destination of the cons 1 cell gets clobbered with a pointer to the cons 2 cell, the new hole is the cons 2 cell's hole, and the top of the data structure is the top of the cons 1 cell.
Here is append in destination-passing style:
appendDPS [] ys dk = fill dk ys
appendDPS x::xs ys dk = appendDPS xs ys (comp dk (dcons x))
where fill dk ys plugs ys into its destination (the hole in dk), comp composes two destinations, and dcons x creates a cons cell with car x and cdr its destination. These combinators allow us to construct lists in a top-down fashion, matching the top-down way we consume them.
It's also well-known that transforming a function into continuation-passing style (CPS) makes it tail-recursive. Take, for example, the append function:
append [] ys = ys
append x::xs ys = x::(append xs ys)
appendCPS [] ys k = k ys
appendCPS x::xs ys k = appendCPS xs ys (λzs. k (x::zs))
appendCPS is tail-recursive, but only because we've cheated: as its goto-based loop iterates, it allocates a closure per element of xs, essentially recording in the heap what append would've allocated on the stack.
A standard trick is to write in accumulator-passing style, which can be thought of as specializing the representation of continuations in CPS. I invite you to try this for append. A hint: there is a reason that revAppend is a common library function.
Sadly, there is a general pattern here. When we want to iterate through a list from left to right, we end up accumulating the elements of the list in the reverse order. The essential problem is that basic functional data structures can only be built bottom up, and only traversed top down. Of course one can use more complex functional data structures, like Huet's zipper, to do better, but we'd like to program efficiently with simple lists.
In a 1998 paper, Yasuhiko Minamide studied an idea that has come to be known as "destination-passing style". Consider a continuation λx.cons 1 x which, when applied, allocates a cons cell. The representation of this continuation is a closure. But this is a bit silly. If we are writing in CPS, we allocate a closure whose sole purpose is to remind us to allocate a cons cell later. Why not allocate the cons cell in the first place? Then, instead of passing a closure, we can pass the location for the cdr, which eventually gets written with the final value x. Hence, destination-passing style.
The fact that the cdr of the cons cell gets clobbered means that the cons cell must be unaliased until "applied" to a final value. Hence Minamide imposes a linear typing discipline on such values.
The other important ingredient is composition: we want to be able to compose λx.cons 1 x with λx.cons 2 x to get λx.cons 1 (cons 2 x). To accomplish this, our representation will consist of two pointers, one to the top of the data structure, and one to the hole in the data structure (the destination). With that representation, composition is accomplished with just a bit of pointer stitching. The destination of the cons 1 cell gets clobbered with a pointer to the cons 2 cell, the new hole is the cons 2 cell's hole, and the top of the data structure is the top of the cons 1 cell.
Here is append in destination-passing style:
appendDPS [] ys dk = fill dk ys
appendDPS x::xs ys dk = appendDPS xs ys (comp dk (dcons x))
where fill dk ys plugs ys into its destination (the hole in dk), comp composes two destinations, and dcons x creates a cons cell with car x and cdr its destination. These combinators allow us to construct lists in a top-down fashion, matching the top-down way we consume them.
Wednesday, May 12, 2010
Staying grounded
Observational equivalence is a cornerstone of semantics: given a notion of observations on complete "programs", you get a notion of equivalence on program fragments. Two fragments are equivalent if no program context they are placed into leads to distinct observations. Contexts transform internal observations, made within the language, to external observations, made by some putative user of the language.
Usually, we can be loose with what we consider an observation. The canonical observation is program termination: a one bit observation. This is equivalent to observing actual values at ground type, since the context
if [] = c then () else diverge
transforms value observations to termination observations.
So let's take termination as the basic observable. It turns out that, as least for call-by-name, it makes a difference where termination is observed: at ground type only, or at all types? Using the former, the programs λx.Ω and Ω are equated, because any CBN ground type context that uses them must apply them to an argument, in both cases leading to divergence. If, on the other hand, we observe termination at all types, then the context [] serves to distinguish them, since the first terminates and the second doesn't. Cf. Abramsky's work with lazy lambda calculus.
I'm curious about the methodological implications. An interpreter for Haskell based on ground equivalence could substitute Ω for λx.Ω, which means a user could type λx.Ω into the REPL and never get an answer. That seems wrong, or at least odd -- but do we care? Do we give up useful equations by observing at all types?
Update: clarified that the above remarks are specific to a CBN evaluation strategy.
Call-by-name, call-by-value, and the linear lambda calculus
I've started work at MSRC, and one of my immediate goals is to get better acquainted with the linear λ-calculus. Girard's linear logic is the archetypical substructural logic: a proof of a linear implication A ⊸ B is a proof of B that uses the assumption A exactly once. The logic is substructural because it lacks two of the "structural rules", namely contraction and weakening, that would permit assumptions to be duplicated or thrown away, respectively. On the other hand, linear logic includes a modality ! (read "of course") under which the structural rules hold. Thus you can prove that !A ⊸ (!B ⊸ !A), throwing away the assumption about B.
Linear logic, via Curry-Howard, begets linear λ-calculus. Here's a simple implicational version:
There is an interesting and natural operational semantics for this calculus, where functions have a call-by-value (CBV) semantics and lets have a call-by-name (CBN) semantics. Rather than exploring that design choice, however, I want to talk about one way to exploit it.
It turns out that intuitionistic logic (IL) embeds, in a certain sense, into intuitionistic linear logic (ILL). The most well-known embedding is (A → B)* = !A* ⊸ B*, so that A is valid in IL iff A* is valid in ILL. The intuition is simple: a proof in IL is just a linear proof in which every assumption is treated structurally. Other embeddings are possible; I'm going to use (A → B)* = !(A* ⊸ B*), for reasons that will become clear momentarily.
The connection between IL and ILL propositions raises a question from the Curry-Howard perspective: can we embed λ-calculus terms into linear λ-calculus terms, such that their types follow the * embedding above? The answer is yes -- and more. Just as Plotkin gave two CPS transformations, corresponding to CBV and CBN semantics, we can map λ-calculus into linear λ-calculus in two ways, again preserving CBV and CBN semantics.
First, the CBV version:
The first thing to notice about this translation is that !-introduction is used only around CBV values (variables and lambdas). Thus the CBN semantics of !-elimination never causes trouble. Variables can be !-ed because they will always be let-bound in this translation. On the other hand, the CBV semantics of linear functions means that in the application M N, the translated argument N* will be evaluated to some !L before substitution -- and, as we already mentioned, L can by construction only be a value. Note that the let-bindings in the translation are not used to force evaluation--after all, they are CBN!--but simply to eliminate the ! that we are wrapping around every value.
The CBN translation differs only in the rule for application:
These translations are adapted from Maraist et al, who attribute them to Girard. I changed the CBN translation, however, to ease comparison to the CBV translation.
Linear logic, via Curry-Howard, begets linear λ-calculus. Here's a simple implicational version:
M ::= x | λx.M | M N | !M let !x = M in Nwhere o is a base type. When a variable x is bound by a λ, it must be used exactly once in the body. When it is bound in a let, it can be used freely in the body. The catch is that in let !x = M in N, M must be of type !τ. Expressions of type !τ are introduced as !M, where M can only mention let-bound variables.
τ ::= o | τ ⊸ τ | !τ
There is an interesting and natural operational semantics for this calculus, where functions have a call-by-value (CBV) semantics and lets have a call-by-name (CBN) semantics. Rather than exploring that design choice, however, I want to talk about one way to exploit it.
It turns out that intuitionistic logic (IL) embeds, in a certain sense, into intuitionistic linear logic (ILL). The most well-known embedding is (A → B)* = !A* ⊸ B*, so that A is valid in IL iff A* is valid in ILL. The intuition is simple: a proof in IL is just a linear proof in which every assumption is treated structurally. Other embeddings are possible; I'm going to use (A → B)* = !(A* ⊸ B*), for reasons that will become clear momentarily.
The connection between IL and ILL propositions raises a question from the Curry-Howard perspective: can we embed λ-calculus terms into linear λ-calculus terms, such that their types follow the * embedding above? The answer is yes -- and more. Just as Plotkin gave two CPS transformations, corresponding to CBV and CBN semantics, we can map λ-calculus into linear λ-calculus in two ways, again preserving CBV and CBN semantics.
First, the CBV version:
x* = !x
(λx.M)* = !(λy.let !x = y in M*)
(M N)* = (let !z = M* in z) N*
The first thing to notice about this translation is that !-introduction is used only around CBV values (variables and lambdas). Thus the CBN semantics of !-elimination never causes trouble. Variables can be !-ed because they will always be let-bound in this translation. On the other hand, the CBV semantics of linear functions means that in the application M N, the translated argument N* will be evaluated to some !L before substitution -- and, as we already mentioned, L can by construction only be a value. Note that the let-bindings in the translation are not used to force evaluation--after all, they are CBN!--but simply to eliminate the ! that we are wrapping around every value.
The CBN translation differs only in the rule for application:
Here again, the lets are just being used to unpack !-ed values. The significant change is the introduction of a ! around the translation of N: it has the effect of suspending the computation of the argument, because in linear λ-calculus, !M is a value.(M N)* = (let !z = M* in z) !(let !z = N* in z)
These translations are adapted from Maraist et al, who attribute them to Girard. I changed the CBN translation, however, to ease comparison to the CBV translation.
Subscribe to:
Posts (Atom)
